Hoe halen we meer uit onze data? Dat vragen we aan onze dataspecialisten, maar waar zitten die in onze organisatie? In een apart hoekje achter grote schermen en dikke computers, tussen de medewerkers in de afdelingen of ergens er tussenin?
Het dataorganisatievraagstuk
Veel overheidsorganisaties worstelen met dit vraagstuk. Een verantwoord datagebruik wordt steeds belangrijker. We nemen dataspecialisten aan – wat vaak al een hele opgave is – en meer medewerkers gaan beschikken over datacompetenties. Omdat ze dat leuk vinden en omdat ze zien dat data helpt om maatschappelijke vraagstukken op te lossen.
In deze blog gaan we in op het organisatievraagstuk dat ontstaat door de komst van de dataspecialisten en het toenemend belang van data bij de uitvoering van publieke taken.
De hoofdrolspelers
Wie komen we hier allemaal tegen? Op de eerste plaats de medewerker die in zijn/haar afdeling ‘meer met data wil gaan doen’. Laten we haar Nuria de datavertaler noemen. Zij herkent in haar afdeling de datavraag en heeft een idee over de mogelijke bijdrage die data kan leveren aan het werk. Daarnaast betreedt Menno het toneel. Menno is als data scientist binnengehaald, omdat we meer data-expertise nodig hebben in onze organisatie om vragen zoals die van Nuria te beantwoorden. Hij kan data-oplossingen bouwen, helpen bij analyse en weet welke techniek helpend is bij welk vraagstuk. We hebben ook nog Julia, die als data engineer de taak kreeg om nieuwe datasets te ontsluiten in het dataplatform (de IT-tooling voor opslag, analyse en gebruik van data). Tot slot hebben we Karel. Karel is de manager die leiding moet gaan geven aan het datateam in oprichting. Karel heeft als opdracht om het datateam op de meest effectieve manier in te richten en een sterke positie te geven binnen de hele organisatie. Wat zijn hierbij zijn mogelijkheden?
De uitersten
We richten een centraal datateam in met eigen mensen en eigen verantwoordelijkheden. Nuria, Menno en Julia worden samen met de andere dataspecialisten in een team geplaatst waar Karel de manager van wordt. Medewerkers uit de afdelingen kunnen aankloppen bij het centrale datateam met hun datavragen en het datateam gaat ermee aan de slag.
Handig om al die specialisten bij elkaar te hebben. Er ontstaat in het datateam veel kennis op datagebied en de dataspecialisten kunnen lekker gestandaardiseerd werken. Er is ook duidelijkheid over het beheer van de data en de dataproducten: dit ligt bij het centrale datateam. Karel is als manager goed op de hoogte van wat er speelt binnen ‘zijn’ team en kan de taken slim wegzetten.
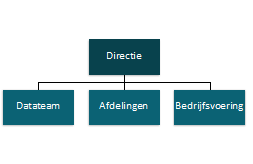 Een centraal datateam werkt vaak goed voor kleine organisaties: de lijnen zijn kort waardoor men het centrale team relatief makkelijk weet te vinden. Ook organisaties waar de datavolwassenheid laag is, kunnen met een centraal team snel voldoende schaal creëren en de eerste stappen zetten met datagedreven werken.
Een centraal datateam werkt vaak goed voor kleine organisaties: de lijnen zijn kort waardoor men het centrale team relatief makkelijk weet te vinden. Ook organisaties waar de datavolwassenheid laag is, kunnen met een centraal team snel voldoende schaal creëren en de eerste stappen zetten met datagedreven werken.
Wat wel onhandig is aan een centraal datateam is dat de afdelingen niet altijd duidelijke datavragen stellen. Doordat Nuria, Menno en Julia centraal in de organisatie werkzaam zijn, hebben zij relatief weinig contact met mensen uit de afdelingen en weten zij niet wat daar speelt. Zij zijn niet altijd goed in staat om de datavragen van de afdelingen te verhelderen. Hierdoor slaat het datateam soms wel erg zijn eigenwijze dataweg in. Op de een of andere manier zijn ze in de afdelingen lang niet altijd tevreden over de dataproducten waarmee het datateam komt.
Er is een alternatief: de dataspecialisten werken volledig decentraal. Elke afdeling heeft zijn eigen dataspecialisten. Nuria kan (gelukkig, vindt ze zelf) in haar eigen afdeling blijven en daar aan 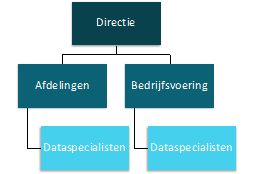 dataprojecten werken. Menno en Julia worden als dataspecialisten toegevoegd aan haar afdeling. Voor Karel is even geen ruimte dus hij moet wat anders gaan doen. Er is immers niet één datateam, dus valt dat ook niet te managen.
dataprojecten werken. Menno en Julia worden als dataspecialisten toegevoegd aan haar afdeling. Voor Karel is even geen ruimte dus hij moet wat anders gaan doen. Er is immers niet één datateam, dus valt dat ook niet te managen.
Handig, die dataspecialisten zo dichtbij het primaire proces in de afdelingen. Hoeven we ook geen nieuwe afdeling op te zetten.
Een decentraal model kan goed werken wanneer in een organisatie verschillende ‘snelheden’ zijn op het gebied van datagedreven werken: een bepaalde afdeling wil sneller dan de andere en heeft zo de vrijheid om met eigen dataspecialisten ambities te realiseren. Ook in hele grote organisaties waarin de afdelingen zeer zelfstandig zijn en weinig tot niks met elkaar van doen hebben, kan een decentraal model goed werken.
Wat onhandig is aan het decentrale model, is dat het de doorontwikkeling van de datakennis van de dataspecialisten belemmert. Bovendien gaat elke afdeling wel erg zijn eigen gang en van efficiënte gestandaardiseerde oplossingen is geen sprake. Wie is verantwoordelijk voor een goed beheer van data en dataproducten? En wat doen we met datavraagstukken die de grenzen van de afdelingen overstijgen?
De derde weg: Hub en spoke (de naaf en de spaken)
Er is nog een ander model. Stel dat we de organisatie als volgt inrichten: we richten een gemeenschappelijk datateam in waar Menno, Julia en en de andere dataspecialisten hun diensten verlenen aan de afdelingen onder aansturing van Karel. De dataspecialisten staan met één been in het centrale datateam en één been in de afdeling(en) waar zij dataproducten voor ontwikkelen. Dit team is de ‘hub’, de naaf in het fietswiel.
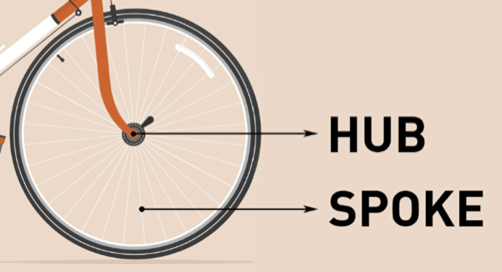 Nuria, onze datavertaler, blijft gewoon op haar afdeling. Ook de andere afdelingen kennen datavertalers die met hun combinatie van vakkennis en datakennis collega’s in de afdelingen helpen om goede datavragen te stellen. Zij staan in nauw contact staan met de dataspecialisten en weten welke oplossingen zij kunnen bieden aan hun afdelingen. Zij vormen de ‘spokes’, de spaken in het fietswiel die stevig verankerd zijn in de naaf en de verbinding vormen met het wiel. De plek waar de meters worden gemaakt.
Nuria, onze datavertaler, blijft gewoon op haar afdeling. Ook de andere afdelingen kennen datavertalers die met hun combinatie van vakkennis en datakennis collega’s in de afdelingen helpen om goede datavragen te stellen. Zij staan in nauw contact staan met de dataspecialisten en weten welke oplossingen zij kunnen bieden aan hun afdelingen. Zij vormen de ‘spokes’, de spaken in het fietswiel die stevig verankerd zijn in de naaf en de verbinding vormen met het wiel. De plek waar de meters worden gemaakt.
Handig, want de spaken krijgen veel kennis vanuit de hub over de mogelijkheden en onmogelijkheden van data voor hun werk, en andersom krijgt de hub via de spokes veel mee van wat er speelt in de afdelingen. Het datateam komt hierdoor niet los te staan van de afdelingen. De kans dat dataprojecten efficiënt en verantwoord gebruik maken van de mogelijkheden is groot. Het gemeenschappelijke datateam kan ook de hele organisatie helpen met het ontwikkelen en uitvoeren van een datastrategie. Zeker als Karel, onze manager, een sterke positie verwerft in het management van de organisatie. De naaf en de spaken maken samen een sterk wiel. Onhandig is wellicht de complexiteit: hoe is de samenwerking tussen het centrale team en de afdelingen? Wat is de balans tussen autonomie voor de afdelingen en het conformeren aan de gezamenlijke afspraken?
Elk model heeft zijn voordelen en nadelen. De omvang van de organisatie, de ‘datavolwassenheid’ en de organisatiecultuur (o.a. de mate van autonomie van de afdelingen) zijn bepalend voor de keuze uit een van de modellen. Voor meer informatie over een effectieve en efficiënte dataorganisatie neem vooral contact op met VKA via gijs.degroot@vka.nl of nico.verbeij@vka.nl.